AI 下一阶段的畅想 -#46
尽管已经有很多大佬分析过 AI 的未来,但我还是想聊聊自己的想法,畅想一下 AI 下一阶段的发展。其主要目的是为了给自己或你们一个参考:作为一个个人投资者或开发者,应该怎么把握住下一阶段的机会,如何发展自己的技能、如何挖到有潜力的公司、如何把握趋势开发出有价值的产品,等等。
上周不管是大厂还是小厂,好像商量好一样,都攒足了劲发布了一系列 AI 产品,让科技圈媒体赶稿都忙不过来了。我看到的有:
- OpenAI 发布了 DALL·E 3,可谓是万众瞩目
- Meta 发布了和雷朋合作的 AI 眼镜,还有最新的 Meta Quest 3
- Google 推出了 Bard Extensions,可以无缝结合 Google 其他生态的数据
- 微软发布了 Windows Copilot,在系统层面为你提供 AI 助手;Bing Image Creator 可以直接使用 DALLE3 了,我试了一下,效果很棒
其实每个星期都有新的 AI 产品诞生,比如前两周发布的 GitHub Copilot Chat 应该是最和我息息相关的了。但这周不知道怎的突然有点激动,可能是因为看了太多的演示视频,也有可能是看了 小扎和 Lex 在元宇宙中的播客,总之就是脑洞大开,突然有点期待 AI 时代的到来。
可能很多人都知道 Amara 定律:我们在短期内会高估一项技术的影响,而长期内低估。距离 ChatGPT 发布已有大半年的时间,人们从最开始的狂热到后来的热情消退,再到现在每天见证新的产品诞生,其实 AI 的进度已经超过了我们的预期,现在的瓶颈反而成了供应端(GPU)。付费就能优先体验更好的模型(更牛逼的 GPU)竟然成了一个很好的商业模式,这是很多人之前没想到的。
尽管已经有很多大佬分析过 AI 的未来,但我还是想聊聊自己的想法,畅想一下 AI 下一阶段的发展。其主要目的是为了给自己或你们一个参考:作为一个个人投资者或开发者,应该怎么把握住下一阶段的机会,如何发展自己的技能、如何挖到有潜力的公司、如何把握趋势开发出有价值的产品,等等。
AI 的层级
上周红杉资本发布了一篇 Generative AI’s Act Two 来对应它们去年发布的 Generative AI: A Creative New World,我觉得这两篇文章很好的概括了从去年开始到现在 AI 的两个阶段。其中最新的 Generative AI’s Act Two 提到了 AI 的基础设施层级,如下图所示:

它把 AI 的层级从下到上依次分为了:
- Foundation Models 基础模型
- Compute & Inference 算力
- Model Tuning 模型调优
- Developer Tools/Infra 开发者工具和架构
- Apps & Workflows 应用和工作流
- Production Monitoring & Observability 产品监控和分析
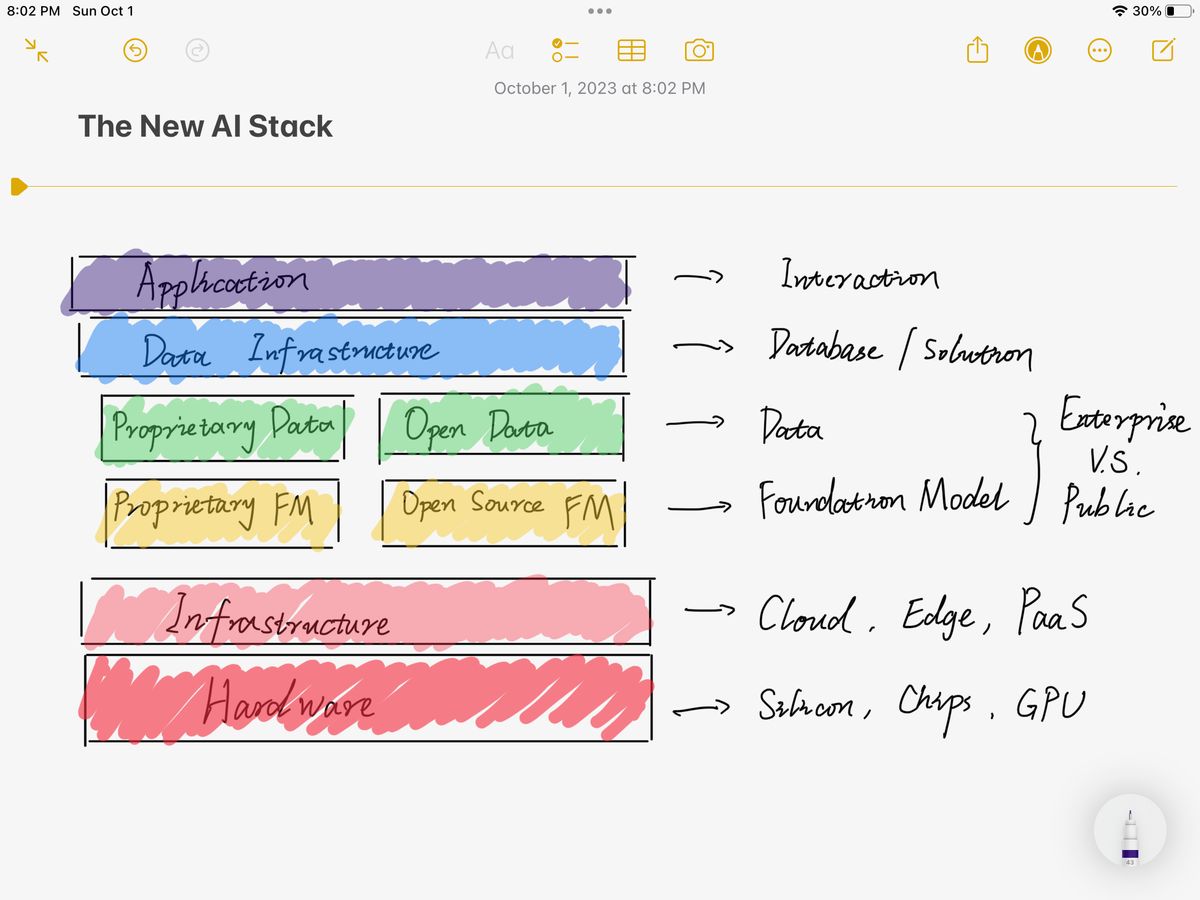
图中每个层级都直接给出了对应的公司,很有参考价值,不过基本上除了大厂都还没上市(当然你也可以迂回地去投)。但我觉得这个划分其实不太符合我一个技术人的直觉,我认为更好的分层应该是像网络 OSI 七层协议一样,从物理层面到交互层面。网络引领了上一个时代,那作为下一个时代的 AI,它的层级应该是下图所示(我自己画的,海涵):
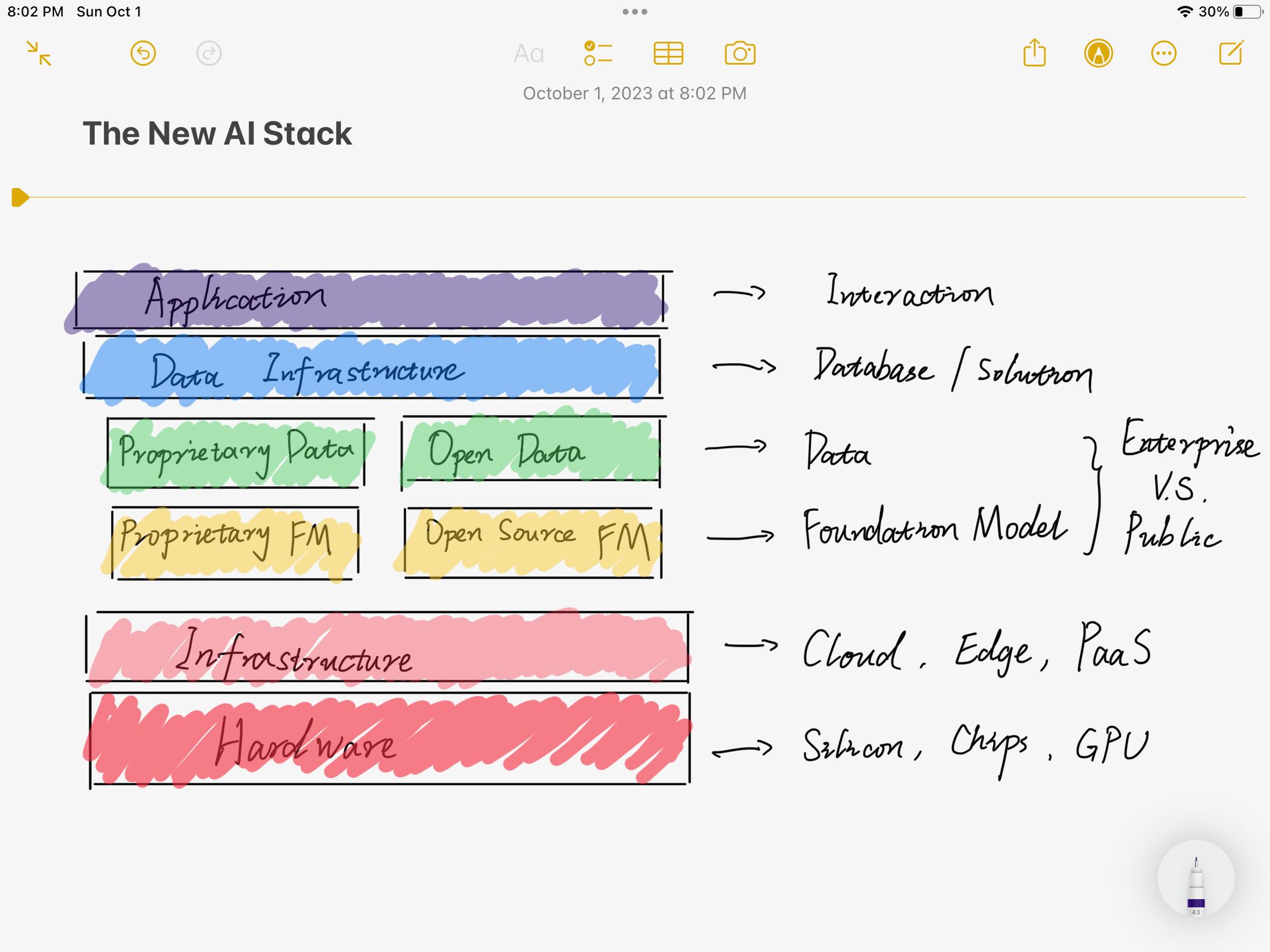
其实从下到上,也很好理解,我们从硬件出发分成了六层:
- Hardware 硬件
- Infrastructure 基础设施
- Fondation Models 基础模型
- Data 数据
- Data Infrastructure 数据基础设施
- Application 应用
硬件很好理解,目前英伟达的显卡都已经被卖爆了,不过这里也不可以忽视其他的大型硬件厂商,比如 Apple Intel AMD 等等。因为众所周知硬件的护城河还是挺高的,未来 AI 需要用到硬件的地方不只是在最底层的训练和模型,而是整个生态每一层都需要。而且未来还有可能出现专有 AI 硬件,对应到应用层或者数据设施层都有可能,比如《硅谷》里面的冰箱...(笑)。
基础设施目前很多大厂在发力的地方,毕竟硬件的供给侧出了问题,大家只能在 Infra 上面卷。现在几乎每家云都提供了 AI SDK,无论是企业还是个人都可以轻松对接,这也是使得 AI 在应用层发展如此迅速的一个原因。还有一些公司在致力于做“弹性扩容”版 GPU,使得未来在 AI 训练上的硬件供给将不再是一个制约。
中间的模型层和数据层是硅谷当红炸子鸡 OpenAI 们正在做的事。我把他们分成了专有/私有和开发/公开两类。它们基本上也分别对应了 toB 和 toC 的两种情况。目前每个公司的套路不一样,训练模型、商业模式、人才战略都各不相同,但又相互渗透,毕竟硅谷就那么大,人才之间的流动带动了整体的繁荣。Meta 选择了开源模型的道路,我个人觉得可能是更有利于小公司和其他层级的路线。另外,尽管现在训练语料的瓶颈似乎还未达到,但在可预见的未来是极有可能出现的,著名科技作者 Benedict Evans 在最近的文章 Generative AI and intellectual property 中提到了 AI 与知识产权的问题。另外在模型长度越来越不受限之后,语料的有效性会迎来挑战,真实的产自人类的预料会越来越稀少,而 AI 生成的预料又会降低模型的可用性,这目前似乎还没有什么好的解法。
Data Infrastructure 层其实主要就是数据库相关产业,数据存储方式的演变可能对后续 AI 的发展也会有很大的影响。比如图数据库是不是会比关系型数据库更适合 AI?
最后的应用层,大家应该每天都能看到无数如雨后春笋般的 AI 应用在发布,同质化已经很严重了,具体哪些能在将来拔得头筹,就很仰仗于我接下来要聊的问题——AI 应用的壁垒。